KubernetesにおいてPod以外、つまりクラスタを維持・管理するためのコンポーネントを中心にそれらの概要をまとめる。 主にKubernetesの公式ドキュメントを基にした内容だが、特にkube-proxyやコンテナランタイムについては様々なページを参考にしている。
これを読むことでKubernetesクラスタにどのようなコンポーネントが存在し、各コンポーネントがどのような役割を持っているかを把握出来る。
Kubernetesクラスタを構成するコンポーネントの一覧
- Control Plane
- kube-apiserver
- kube-scheduler
- Controller (kube-controller-manager, cloud-controller-manager)
- etcd
- Node
- kubelet
- kube-proxy, kube-dns
- Pod (コンテナランタイム)
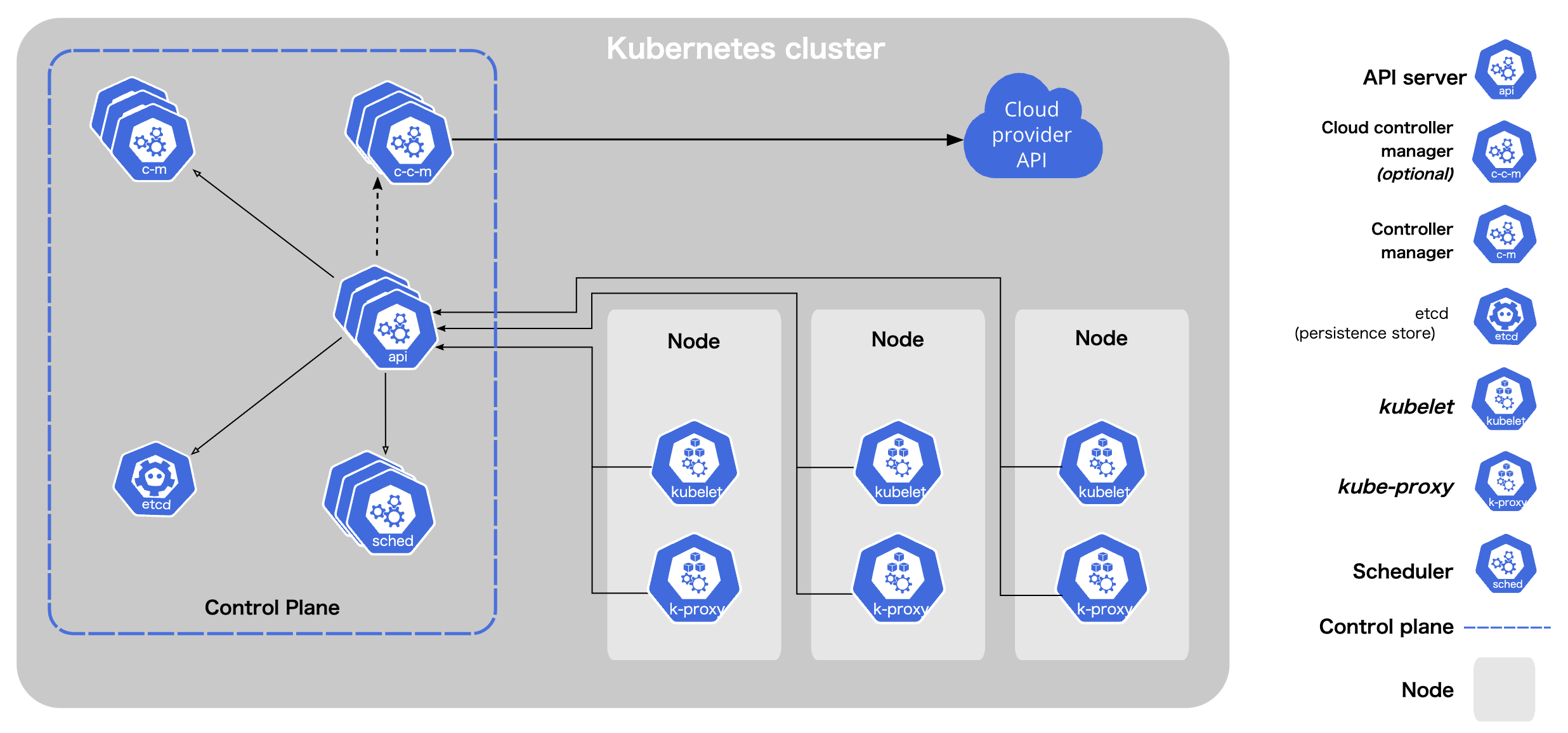
これらのコンポーネントは基本的に非同期でそれぞれが独立してその役割を果たしている。続けてこれらの各要素の概要を説明する。
1. Control Plane
Kubernetesではクラスタに対してPodを追加するなど何らか変更を行う際にも、クライアントがNodeと直接やり取りしてPodを追加や変更することはできない。ここでのクライアントとは具体的にkubectlなどのこと。
Podを含むクラスタに対する変更や監視あるいはそれらの稼働状況の維持はControl Planeが行い、クライアントはControl Planeに対して変更を依頼するというアーキテクチャになっている。
そしてControl Planeは役割を分担している複数のコンポーネントから成る。
*Control PlaneはかつてMasterとも呼ばれていたが現在は主にControl Planeという名称が使われている。ただし、今でも特にWorker Nodeとの対比でMaster Nodeと呼ばれることもある。
1.1. API Server
KubernetesのAPIを外部に公開するためのコンポーネントであり、これがクライアントからの変更を受け付ける。
変更を受け付けたAPI Serverはetcdにクラスタの情報を保存したうえでクラスタのリソース管理を行う。
Kubernetesクラスタ内の各コンポーネントも基本的にAPI Serverを介してやり取りする。 つまりAPI ServerはKubernetesクラスタ内のHubのようなコンポーネントといえる
1.2. kube-scheduler
まず前提として新たに作成されたPodは複数あるNodeのうちのいずれか一つで実行される。
kube-schedulerはPodをどのNodeで実行するかというNode割当状況を監視しており、Nodeが未割り当てのPodを見つけると、そのPodをどのNodeで実行するかの決定を行う。
つまり新しく作成されたPodはkube-schedulerによってどのNodeで実行するか決定される。
ここでPodをどのNodeで実行するか決めることを「スケジューリング」という。
1.3. Controller
KubernetesはPodの実行および終了だけでなくPodなどのオブジェクトの稼働状況を維持することも重要な役割であり、それこそがDockerやDocker Composeとの大きな違いの一つといえる。
そんなオブジェクトを監視し目指すべき状態に維持する責務を持つのがController。
Controllerは基本的にKubernetesのオブジェクトの種類ごとに存在する。 Controllerも基本的にAPI Serverを介して状態の管理を行うが、API Serverを経由せず直接アクションを実行するようなControllerもある。
kube-controller-manager
前述のように複数ある個別のコントローラプロセスの実行およびその管理を行う。
参考: Kubernetesドキュメント kube-controller-manager
cloud-controller-manager
Kubernetesクラスタ外のPublic Cloudリソースとやり取りおよびKubernetesクラスタにおいて管理するためのコンポーネント。
NodeやServiceなどはPublic Cloudによって作成および管理されうるコンポーネントなのでそれらのコントローラはkube-controller-managerとcloud-controller-managerの両方にまたがって扱われる。
参考: Kubernetesドキュメント cloud-controller-manager
1.4. etcd
Kubernetesの全てのクラスター情報の保存場所として利用されるKVS
2. Node
Podを実際に実行するためのマシンリソース。 Nodeは1つではなく複数になりうる。
Node自体もControl Planeによって管理されており、設定によってはNodeの実行も状況に応じて動的にスケール出来る。
Node内ではPodおよびコンテナを実行するためのコンテナランタイム以外にもPodを管理するkubeletやkube-proxyが含まれる。
Worker Nodeとも呼ばれる。
2.1. kubelet
Node上でPodの管理するエージェント。Podの実行や終了の際にPodとやり取りする。各Nodeごとにkubeletが存在する。
2.2. kube-proxy, kube-dns
Podへアクセスするためのネットワークプロキシの役割を持つ。 つまりkube-proxyはServiceの機能を実現するために、Serviceの仮想IPアドレスの管理、Pod自体のIPアドレスとServiceの紐づけを行う。これらのルーティングには主にiptablesが利用されている。
kube-proxyもnodeごとに存在しているが、kube-proxy自身もpodとして実行されている。
ルーティングとはまた別にKubernetesにおける名前解決にはkube-dnsあるいはCoreDNSというコンポーネントが利用される。
kube-proxyやkube-dnsについての参考URL・資料
- Kubernetesドキュメント
- 『入門 Kubernetes』Kelsey Hightower、Brendan Burns、Joe Beda 著、松浦 隼人 訳 オライリー・ジャパン
- Kubernetes のサービスとは (1) 大雑把な理解
- Kube-Proxy: What Is It and How It Works
- Kubernetes の Service (Cluster IP) がどう実装されてるか
- クラスタ起動時に立ち上がるkube-dnsは何をしているか?
- その他。そもそものクラスタのネットワークについて
2.3. Pod
アプリケーションのコンテナを実行するためのコンピューティングを担当するオブジェクト。このPod内でコンテナが実行され1つのPod内で複数のコンテナが実行されうる。 Pod内のコンテナ同士はlocalhostで通信可能であり、他にも様々なリソースを共有している。
Kubernetesを使う際には基本的に直接Podを扱うことは多くなく、DeploymentやJobなどより上位のワークロードリソースを通じてPodを実行することになる。
コンテナランタイム (CRI)
コンテナの実行を担当するソフトウェア。 コンテナランタイムを通じてPodを操作することが出来る。
CRIはkubeletが低レベルランタイムのためのOCIを意識することなく高レベルランタイムとやり取りするためのインターフェース。
コンテナランタイムについての参考URL
- Kubernetesドキュメント コンテナランタイム
- Introducing Container Runtime Interface (CRI) in Kubernetes | Kubernetes Blog
- Kubernetes の コンテナランタイムについて、改めて見つめなおしてみた
- コンテナランタイムの動向を整理してみた件
- KubernetesのDockershim廃止における開発者の対応
Kubernetesを学んで思うところ
上記のそれぞれの役割からも分かるようにKubernetesはクラスタを維持管理するために多くのコンポーネントが互いに作用している。
Kubernetesはある種のOS特にLinuxカーネルのようなものといえる。 従来のOSは基本的に一つのマシンに対して、そのマシン内のCPUやメモリその他リソース状況を把握しつつプロセスの実行を管理している。 複数のNodeにまたがりはするがKubernetesも限りある各Nodeのマシンリソースを考慮した上で、各Podの実行を管理するという意味ではまさにOSといえる。 Kubernetesにおいても「スケジューリング」やこの記事では触れていないが「プリエンプション」という用語や概念がありOSなどのマルチタスク管理に必要な考え方が使われている。
よってこの印象はそこまで間違っていないと言えそう。現に似たような視点を持った記事はいくつか見つかる。 (具体例)
Kubernetesは新たに覚えるべき事柄も多く理解や実運用出来るようになるまでのハードルは高い。しかしKubernetes登場以前は大規模な分散システムを扱う際にそれぞれの組織が独自のノウハウを蓄積しながらやっていたようなことが、Kubernetesによって同一のフレームワークで分散システムのスケーリング手法がある程度共通化され、共通の語彙で知見を流用することが出来るようになる。
また、本記事ではあまり触れていないがPodをスケールさせる仕組みにおいては様々な要素が関係するためより複雑であるが、矛盾なくクラスタをスケーリングさせるためには必要な仕組みであることも理解できる。
よってKubernetesは最初のとっつきにくさや理解のハードルの高さはあるが、より普及することやこれを学ぶことには一定の価値があると納得できるようになってくる。